Deep Interpretable Models
Thomas Dooms * , Ward Gauderis * , Geraint A. Wiggins , Jose Oramas
Overview
Previous work in weight-based interpretability was limited to single layer analysis. To interpret deeper models, sparse dictionary learning was necessary to divide into subproblems. Ideally, we would want to extract features, purely from the weights, even in deeper models.
This paper introduces a theoretic framework toward scalable weight-based interpretability. These insights are used toward a new algorithm that globally decomposes the weights of a model, akin to SVD. While this algorithm optimises toward rank, it naturally finds sparse structure, which is easy to understand.
This decomposition can be used to find the globally most important eigenvectors for each output class. We study a multi-layer image model trained on the SVHN dataset (a more challenging variant of MNIST that single layer models can’t solve).

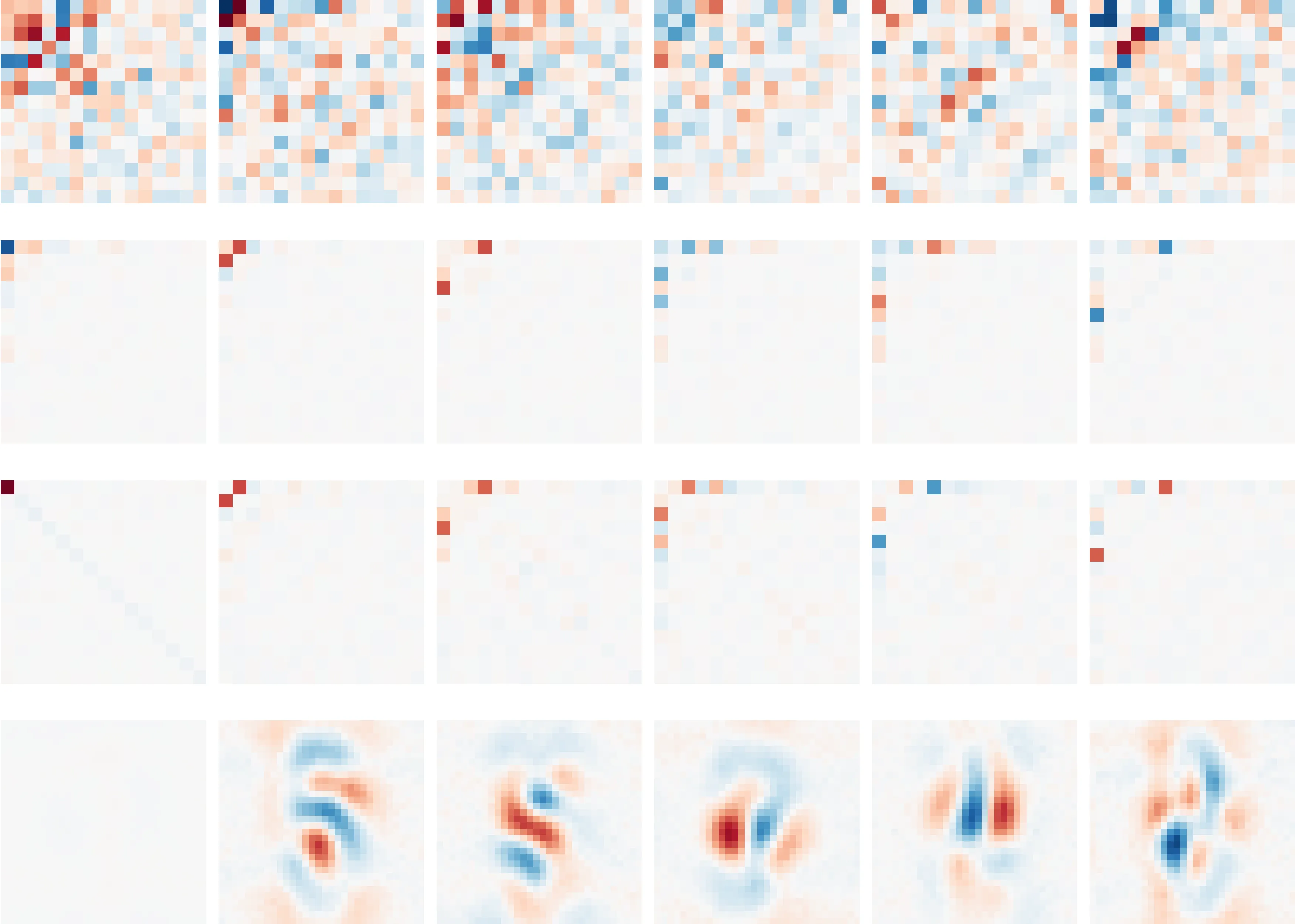
Top eigenvectors (extracted from the weights) per class of a 3-layer SVHN classifier.
The decomposition can also be used to morph the model into a sparse compositional tree. The bottom row of this figure shows the most important ‘features’ to the model. These reveal important strokes or proto-digits, hinting the model has learned sensible structure. The next layers represent ‘interaction matrices’, which describe how features interact. The first two layers only combine a handful of features together. The last layer densely (but still low-rank) combines these composed features into a prediction. Tracing out paths through this tree shows how the model forms specific predictions.